В связи с возросшей информатизацией современного общества и увеличением числа объектов и потоков информации, которые необходимо защищать от несанкционированного доступа, а также необходимостью интеллектуализации всех форм взаимодействия пользователей автоматизированных систем управления с техническими средствами все более актуальными становятся проблемы использования механизмов речевых технологий для разграничения доступа к ИВС. Сегодня мы находимся на очередной стадии технической эволюции данных систем. Уже появились первые коммерческие версии программного обеспечения, использующего речевые технологии. Однако если в середине текущего столетия системам распознавания речи и идентификации по голосу предрекали в недалеком будущем повсеместное применение, то сегодня они оказываются работоспособны только в определенных сферах общественной жизни, так и не получив широкого распространения.
Проблема идентификации личности по голосу
За последние несколько десятилетий можно отметить возросший интерес к проблеме идентификации по голосу. Прежде всего он обусловлен преимуществами установления и проверки подлинности личности по отрезку речевой волны: голос невозможно украсть, а в процессе идентификации не требуется непосредственный контакт с пропускной системой, С ростом использования современных речевых технологий (запросы о состоянии банковских счетов и банковские расчеты по телефону; запрос информации из баз данных по телефону; автоматическая оплата междугородных телефонных переговоров и т. д.) возрастает необходимость установления подлинности абонента. Важным применением методов идентификации говорящего по голосу является проверка прав доступа к различным объектам (информационным и физическим): каналам связи; вычислительным системам; базам данных; АСОД; банковским счетам; служебным и индивидуальным помещениям ограниченного пользования (секретность, материальные ценности и т. д.).
Необходимо отметить, что многие современные средства защиты недостаточно надежны, так как основаны на использовании какого-либо пароля, физического ключа или кода, который можно потерять, подобрать, подсмотреть, сломать, передать злоумышленнику под воздействием силы. Поэтому всегда существует возможность атаки на любую систему обработки информации. Злоумышленник попытается завладеть ключом или паролем, прежде чем взламывать систему другими способами. Поэтому пользователю всегда необходимо иметь при себе надежный и постоянный «ключ», удобный для использования и недоступный злоумышленникам. Очевидно, что таким универсальным «ключом» могут быть биометрические параметры личности: отпечатки пальцев, динамика и вид подписи, изображение, голос. Исследования показали, что на современном этапе разработанные способы моделирования речевого сигнала и методы выделения индивидуальных параметров диктора открывают возможность создания надежных систем идентификации личности на основе речи. Однако необходимо отметить, что вероятность взлома такой системы нарушителем будет зависеть от выбранных параметров, характеризующих индивидуальность голоса человека, от выбранного режима обучения, от концепции построения системы идентификации и т. д.
На сегодняшний день созданы десятки различных систем идентификации по голосу, имеющих различные параметры и требования к процессу идентификации в зависимости от конкретных задач. В нашей стране разработан ряд законченных программных продуктов, которые уже нашли применение в различных ведомствах, например программно-аппаратная система текстонезависимой идентификации говорящего «СИГ», программно-аппаратная система разграничения доступа к информационным ресурсам на основе верификации говорящего по парольным фразам «Голосовой ключ» (используется в Министерстве обороны), автоматизированная система идентификации лиц по фонограммам русской речи «Диалект» (используется в Министерстве внутренних дел).
К сожалению, на сегодняшний день разработанные программы не отличаются простотой обучения, удобством работы или низкой стоимостью. Чаще они применяются как дополнительные средства проверки подлинности там, где необходимо обеспечить высокую степень надежности систем идентификации. Поэтому сегодня продолжаются работы по совершенствованию алгоритмов обработки речевых сигналов с целью создания механизмов автоматического опознавания человека по голосу, более адекватных процессу восприятия речи человеком.
Параметры речевого сигнала и фактор индивидуальности
С проблемой идентификации личности своих родственников или друзей человек постоянно встречается в своей жизни. Он делает это неосознанно и быстро на основе своего жизненного опыта и достаточно большого объема информации (внешний вид, походка, голос, манера поведения), что делает на первый взгляд проблему идентификации достаточно прозрачной и очевидной. Поэтому вопрос «Что же позволяет нам отличать голос одного человека от другого?» приводил первых исследователей к чисто умозрительным теориям. В основном это происходило из-за недооценки сложности речи как многофункционального акта коммуникации между людьми, включающего в себя как информацию об индивидуальном голосе говорящего, так и информацию о фонетическом качестве. Поэтому очень важно обеспечить правильный выбор и обоснование системы признаков, которые затем определят принцип построения системы идентификации. Вопрос заключается в следующем: каковы же объективные предпосылки узнавания человека по голосу? Какие физические явления лежат в основе процесса распознавания дикторов? Какие акустические характеристики могут быть использованы для построения системы идентификации?
На основании данных, полученных с помощью опытов, использующих субъективные методы, основное проявление индивидуальности речи человека следует искать в двух основных группах признаков. Они связаны с физиологическими (анатомическими) особенностями механизма речеобразования человека и уникальным характером приведения его в действие (артикуляционной деятельностью), обусловленным работой центральной нервной системы.
Первая группа признаков основывается на хорошо известной модели речевого тракта [3], состоящей из передаточной функции резонансной системы и генератора импульсов сигнала возбуждения. Передаточная функция практически полностью характеризует индивидуальную геометрическую форму полостей речевого аппарата: задняя глоточная полость, сужение между языком и небом, передняя полость рта, сужение между губами и т. д. Основными параметрами здесь выступают характеристики четырех формантных областей (средняя частота, частотный диапазон, энергия), огибающая спектра, формантные траектории и производные от этих параметров. Частота импульсов возбуждения находится в прямой зависимости от колебаний голосовых связок, которые, в свою очередь, зависят от длины, толщины и натяжения последних. Основными параметрами здесь являются частота основного тона, параметр тон/шум, звонкость, подъем основного тона и производные от этих параметров.
Для расчета параметров, связанных с физиологическими особенностями речевого тракта, наиболее часто используются методы спектрально-временного анализа. Такие методы анализа речевого сигнала адекватны природному механизму восприятия речи [2], что делает понятной тенденцию многих исследователей искать индивидуальные особенности в мгновенных спектральных распределениях отдельных фонем и в распределениях текущего спектра. В основе таких методов лежит классический Фурье-анализ [3] или параметрический авторегрессионый анализ (линейное предсказание как частный случай) [4,5].
Тесно связан со спектральным представлением речевого сигнала довольно часто применяемый в последнее время гомоморфный метод [4]. Этот метод представляет речевой сигнал в виде последовательности векторов кепстральных коэффициентов, которые требуют значительно меньшего объема памяти для хранения эталонных образов. Небольшим количеством кепстральных коэффициентов (обычно 8 или 16) можно аппроксимировать формантный разрез, имеющий высокое спектральное разрешение. Это обеспечивает более компактное представление речевых отрезков без существенной потери основных информативных признаков (формантной структуры, огибающей, параметра тон/шум).
Что касается параметров сигнала возбуждения, то они могут быть рассчитаны одним из широко известных методов выделения частоты основного тона (например корреляционный метод, кепстральный метод, метод Голда—Рабинера [3,4]).
Если первая группа признаков отражает статические свойства речеобразующего тракта, то вторая группа призвана полностью описать его поведение во времени, то есть артикуляционную динамику речи. Согласно существующему предположению, исходным и основным этапом в организации процесса речеобразования является управляемая центральной нервной системой человека программа комплекса артикуляционных движений, соответствующая тому сообщению, передача которого планируется в данный момент времени [1, 2]. Не вызывает сомнения тот факт, что индивидуальный характер результата речевой активности определен уже на уровне центральной нервной системы, то есть на уровне синтеза артикуляционных программ. Решающими факторами этого процесса являются такие моменты, как социально обусловленные речевые навыки говорящего, его индивидуальный опыт, психологический склад (в частности, темперамент), характерологические особенности и даже интеллект. Управление речевым процессом не может осуществляться без этих основных компонентов. Необходимо отметить, что под артикуляционной программой подразумевается такая программа, которая содержала бы правила произнесения определенных структур. Эти правила относятся к управлению интонацией речи, ее ритмикой, ударением, громкостью, то есть к управлению просодическими характеристиками речи. При этом артикуляционная программа распространяется на такую смысловую единицу речи, как синтагма. Под синтагмой понимается ритмико-мелодическая единица речи, грамматически оформленная и выражающая в пределах более сложного целого (например предложения) относительно законченную мысль. В рамках одной синтагмы выделяются супрасегментные характеристики или интонационные характеристики речевого потока. Основными параметрами здесь выступают интенсивность, мелодия или движение основного тона, система ударений, временные характеристики (длительность сегментов, пауз, темпа), ритмическая картина речевой фразы.
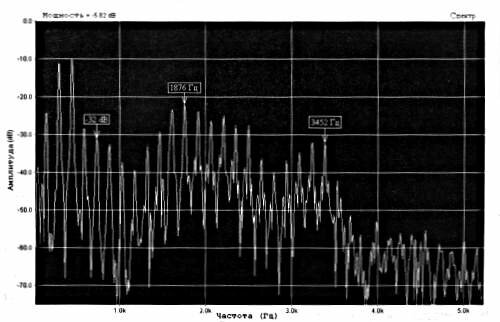
Исследование ритмической картины речевой фразы показало, что ее временной рисунок остается инвариантным для индивидуальной артикуляционной программы, независимо от абсолютных длительностей отдельных слов и слогов, входящих в ее состав, то есть остается инвариантным относительно темпа речи [1]. Это положение позволяет допустить существование в центральной нервной системе некоторых уникальных для каждого человека схем, обеспечивающих генерирование определенной и повторяющейся последовательности действий речевого аппарата во времени. При анализе внутрислоговой артикуляции было выявлено, что хотя она и является результатом последовательных движений, можно предположить, что эти движения не диктуются центральной нервной системой последовательно одно за другим, а получаются рефлекторно.
Для расчета параметров, описывающих артикуляционную динамику речи, могут быть использованы методы спектрально-временного анализа данных, описанные выше. Однако необходимо отметить такую особенность расчета просодических параметров, как их жесткая связь с лексическим и синтаксическим контекстом исследуемой фразы. Это требует комплексного применения как средств лингвистического анализа, так и параметрических методов обработки, что явно определяет сложность анализа данных характеристик. При этом основной задачей является установление прямой связи между деятельностью речеобразующего аппарата (динамикой его артикуляционных движений) и характеристиками спектральной картины потока речи.
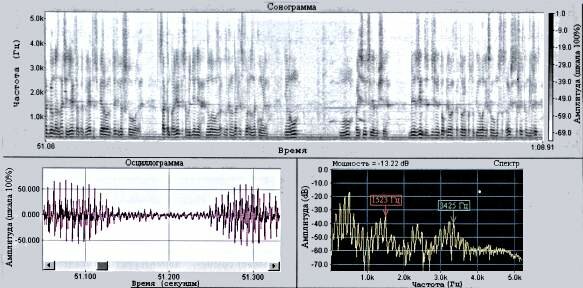
Продолжая разговор о параметрах речевого сигнала, определяющих индивидуальность голоса человека, необходимо затронуть вопрос об интегральных параметрах речи. Эти параметры в силу своей природы не могут быть отнесены ни к одной из указанных выше характеристических групп, но сильно коррели- рованны с ними и формируются под воздействием анатомических особенностей речеобразующего тракта и артикуляционной деятельности человека.
Субъективные методы исследования позволяют установить, что конкретный источник голоса существует в речевом сигнале в виде некоторого постоянного фона. Слух человека, легко фильтруя необходимую ему информацию, осуществляет постоянное слежение за окраской голоса. Иногда совсем не различая фонетические элементы речи и даже смысл произносимого предложения, человек тем не менее легко идентифицирует говорящего по характерному потоку параметров голоса.
Это обстоятельство натолкнуло многих исследователей на мысль использовать в качестве характерных признаков голоса некоторые интегральные свойства речевого сигнала, то есть свойства, проявляющиеся в виде усредненных значений на отрезке всего анализируемого сигнала. Если длительность сигнала представлена со статистической точки зрения и его продолжительность позволяет проявиться таким законам языка, как закономерность появления частот отдельных фонем, то считается, что анализ интегральных параметров речевого сигнала дает возможность определить особенности индивидуального произношения для речевых отрезков различного фонетического содержания. Такое предположение хорошо согласуется с повседневным опытом, когда устойчивая идентификация диктора не зависит от фонетического содержания речи.
Один из самых широко распространенных интегральных признаков является средневзвешенный спектр речи. Несмотря на то что данный параметр голоса является наиболее простым видом обработки первичных данных, он считается одним из эффективных признаков идентификации голоса в потоке слитной речи. Важное, а в ряде случаев и решающее значение имеет высота голоса диктора, которая может быть выражена в виде среднего значения частоты основного тона речевого сигнала на фиксированном отрезке времени. Кроме того, данный параметр может быть представлен в виде диаграмм распределения периодов основного тона.
Таким образом, описанные выше параметры речевого сигнала характеризуют различные аспекты голосообразования человека. В зависимости от выбранной концепции построения системы идентификации ее основу будут составлять разные параметры. Большинство из них анализируются классическими методами, другие требуют специальных режимов выделения и обработки, о чем будет сказано ниже.
Принципы построения систем автоматического опознавания дикторов
Большинство разработанных на сегодняшний день систем идентификации личности по голосу построены на основе однократной проверки соответствия требуемой ключевой фразы и произнесенной в первоначальный момент доступа к вычислительной системе. Данные системы поддерживают два основных режима работы: обучение системы и проверка подлинности при доступе.
В первом режиме (регистрация) пользователю предлагается несколько раз произнести ключевую фразу (пароль), ограниченную, как правило, по длительности 3-4 секундами. При этом обучение системы идентификации проводится на усредненных речевых отрезках по результатам записи нескольких произношений. Записанный ключ может храниться в полном объеме или сжиматься эффективными алгоритмами, которые позволяют сохранять индивидуальные параметры голоса без искажения (методы линейного предсказания). Некоторые системы удаляют из записанной ключевой фразы слабовыраженные речевые участки (паузы, шумы, всплески энергии) путем ее деления на отрезки, соответствующие фонемам базового языка, из которых затем выделяется совокупность требуемых параметров. Как правило, в описанных выше системах используются параметры, связанные с анатомическими особенностями речевого аппарата и интегральные параметры. Для исключения возможности подмены или уничтожения эталонных фраз они хранятся в защищенных от записи файлах.
В режиме верификации произнесенная ключевая фраза сравнивается с эталонной с помощью методов вычисления расстояний
![]()
в параметрическом N-мерном пространстве между двумя реализациями, где N - размерность параметрического вектора, а М - количество упорядочных по времени векторов. Если значение
![]()
не превышает установленного порога идентификации, принимается решение о положительном определении данного голоса.
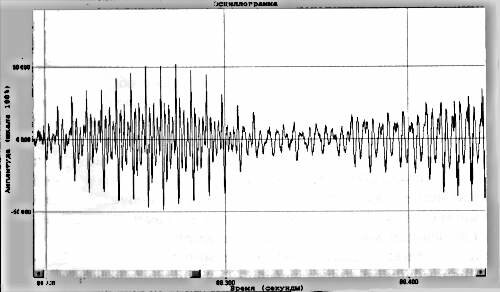
Для систем, которые проводят анализ индивидуального произношения отдельных звуков, решение принимается путем расчета взаимно корреляционной функции параметров эталонных и контрольных фонем по максимуму главного лепестка.
Основным достоинством описанных выше систем является простота построения. Широкие возможности их реализации на основе стандартных процедур цифровой обработки сигнала (ЦОС) и невысокие требования к вычислительным ресурсам и объему памяти ЭВМ сделали такие системы почти хрестоматийным примером при изучении теории автоматического определения человека по голосу.
Однако ряд существенных недостатков ограничивают их широкое применение. Прежде всего, такие системы имеют высокое значение ошибок первого («ложная тревога») и второго («пропуск цели») рода. Это связано со сложностью одинакового произношения ключевой фразы при каждом доступе в систему (кратковременная вариативность) и анатомическими изменениями речевого тракта в течение жизни (долговременная вариативность). В связи с этим пароль может быть произнесен с различным темпом и интонацией, в различном эмоциональном состоянии, в условиях заболевания речевого аппарата диктора. Стабильность параметров ключевой фразы зависит от различных акустических условий записи и распознавания, от изменения дистанции до микрофона, от условий внешних шумов и т. д. Данные факторы неизбежно размывают области распознавания в N-мерном параметрическом пространстве, соответствующие конкретным голосам, а при большом количестве пользователей приводят к значительному их перекрытию. Для уменьшения эффектов вариативности параметров распознавания и длительности произношения почти в каждой системе идентификации, построенной по описанному выше принципу, используются механизмы нормализации. При этом необходимо отметить, что процедуры нормализации, «притягивая» к ближайшему центру области распознавания исследуемый вектор, неизбежно деформируют соседние области, оставляя процент их перекрытия тем же. Поэтому использование таких процедур не изменяет значения ошибок первого и второго рода. Минимизация ошибок первого и второго рода может быть достигнута лишь путем выбора высокоинформативных и некоррелированных между собой признаков, обеспечивающих минимальное перекрытие распределений параметров идентификации в векторном пространстве.
Однако при заданном алгоритме обучения, метрическом пространстве и известном вероятностном распределении индивидуальных параметров существует задача оптимального выбора порога идентификации. Порог идентификации выражается соотношением ошибок первого и второго рода, и его значение диктуется конкретными задачами и областью применения системы идентификации. В тех случаях, когда необходимо максимально воспрепятствовать проникновению постороннего лица, следует минимизировать ошибку второго рода за счет максимизации ошибки первого рода. Увеличение ошибки первого рода, то есть редкий пропуск «цели» создает тяжелые условия также и для допуска «своего» лица, что потребует увеличения числа перезапросов системы. В случаях когда «свой» пользователь должен быть допущен с первого произнесения, соглашаясь при этом с возможностью проникновения «чужого», следует минимизировать ошибку первого рода за счет максимизации ошибки второго рода.
Как правило, в надежных системах идентификации авторы программ вынуждены идти по первому пути, что требует от пользователя повторного произношения пароля, а то и полного отказа в доступе, в случае если его голос изменен в результате заболевания речевого аппарата. Поэтому пользователи вычислительных систем, как правило, отказываются от таких механизмов идентификации, возвращаясь к традиционному и более удобному вводу пароля с клавиатуры.
Кроме того, системы, построенные по описанному выше принципу, могут быть взломаны, если нарушитель обладает записанным фрагментом ключевой фразы, которую он мог подслушать или получить под воздействием силы. Поэтому более сложные системы идентификации для решения проблемы «подмены» ключа используют некоторую базу паролей, сформированную системой на этапе обучения. В данной концепции система идентификации случайным образом выбирает пароль из этой базы и предлагает пользователю каждый раз произнести новую ключевую фразу. Поскольку злоумышленник не знает заранее, какой пароль будет предложен системой для произношения, он не может воспользоваться записанным ключом. Данные системы называются текстозависимыми и требуют использования алгоритмов определения фонемного состава ключевой фразы. Как правило, в таких системах не проводят лингвистического анализа речевого сигнала, ограничиваясь только соответствием параметров фонем в начале и конце ключевой фразы и эталона.
Сложность реализации данного механизма идентификации заключается в формировании базы паролей с достаточно большим количеством ключей для каждого пользователя, Режим обучения в таких системах может занимать большое количество времени (до нескольких часов). Не исключено также, что при использовании современных алгоритмов и оборудования цифровой обработки речи у нарушителя появится возможность синтезировать ответы легитимного пользователя на основе его индивидуальных моделей фонем (преобразователи текст - речь). Хотя синтезированная фраза будет отличаться от реально произносимой, особенно в местах перехода от фонемы к фонеме, обнаружить искажения может только мощный аналитический механизм человеческого слуха, но не система идентификации, построенная по описанному выше принципу.
Учитывая описанные выше недостатки существующих механизмов разграничения доступа, в последнее время проводятся активные исследования по возможности построения диалоговых систем идентификации личности по голосу. В отличие от большинства существующих систем идентификации, диалоговые системы основаны на анализе просодических характеристик (вторая группа признаков), которые наиболее ярко выражены не при однократном произношении отдельных ключевых слов, словосочетаний и даже предложений, а в осмысленном акте коммуникации между людьми. Этим объясняется стремление построить алгоритмы идентификации в рамках модели общения человека и ЭВМ. Просодические характеристики обладают свойством устойчивости к изменению акустической обстановки, кратковременной и долговременной вариативности параметров речеобразующего тракта диктора.
Необходимо отметить, что проблема диалога человека и ЭВМ является частью общей проблемы создания систем искусственного интеллекта и находится на стыке нескольких наук, что свидетельствует о ее сложности. Поэтому предлагается за основу системы диалогового общения человека и ЭВМ принять систему преобразования речь - текст, на базе которой может быть создана система речевого управления ЭВМ. В отличие от текстозависимых систем идентификации в диалоговом методе реализуется не только однократный ответ пользователя на запрошенное предложение или вопрос из базы паролей, но и расширение его до полноценного речевого интерфейса ЭВМ. Машина принимает команды от пользователя и выполняет их только в том случае, если голос диктора соответствует зарегистрированному. Такая концепция построения системы разграничения доступа к ЭВМ определит ее конкурентоспособность и устойчивость к внешним нападениям.

Особенностью разрабатываемой системы разграничения доступа является то, что процедура идентификации на основе просодических характеристик включена в процесс обработки команд или сообщений, поступающих от оператора. Такая интеграция позволяет исключить основной недостаток просодического анализа — необходимость большого объема выборок речевого сигнала для обучения и, соответственно, большого времени и памяти ЭВМ. В процессе речевого управления ЭВМ система идентификации получает достаточный объем речевого материала незаметно для самого диктора. Данный подход позволяет исключить отдельный режим обучения системы и вынести его на этап работы пользователя с ЭВМ. Очевидно, что в данном случае целесообразно построить систему идентификации как систему реального времени.
Применен че командной системы в режиме однократного доступа к объекту (например на контрольно-пропускном пункте) не позволит достигнуть требуемого эффекта из-за сложности обучения системы и анализа коротких ключевых фраз. В случае же частого и продолжительного «общения» человека с одним и тем же объектом (например персональной ЭВМ) накапливается статистика об артикуляционной деятельности пользователя на больших объемах речевых данных, что позволит значительно сократить количество допускаемых системой ошибок.
Как уже было отмечено выше, просодический анализ наиболее эффективен в условиях реальной речевой активности диктора, что требует разработки систем командного управления и преобразования речь - текст в потоке слитной речи. Данные механизмы решают противоположную задачу по сравнению с описанными выше системам. Если системы идентификации анализируют различие между произношением конкретных пользователей, то механизмы распознавания речи должны определять общее. Данная задача является частью общей проблемы автоматического распознавания и понимания речи.
Литература
1. Рамишвили Г. С. Автоматическое опознавание говорящего по голосу. М.: Радио и связь, 1981.
2.Блум Ф. Лейзерсон А., Хофстедтер Л. Мозг, разум и поведение. М.: Мир, 1988.
3.Рабинер Л., Шафер Р. Цифровая обработка речевых сигналов. М.: Радио и связь, 1981.
4. Маркел Дж., Грей А. X. Линейное предсказание речи / Пер. с англ. М.: Связь, 1980.
5.Марпл-мл. С. Л. Цифровой спек- тральный анализ и его прило- жение / Пер. с англ. М.: Мир, 1990.